广告人群定向扩充算法综述
本文由 简悦 SimpRead 转码, 原文地址 zhuanlan.zhihu.com
最近因工作需要,我调研了实现广告圈人的相关的算法模型,下面分享下我的调研结果。
背景目标
广告圈人、人群包扩充、人群优选、受众定向、人群定向扩充、广告精准投放...
广告圈人:目标增加公司的收入。是现在广告主有一批待投放的广告,我们通过算法给用户排序,取出 top-k 的用户 为我们的目标人群,这时各个广告主通过一个出价策略计算出一个出价排序,我们给出价最高的广告主投放广告给这批目标人群。我们关注的是用户的下单情况也就是转化率 CVR,作为在实际投放中人群转化效果的评估指标。
举个栗子:对于一个电脑类的广告主,需要对 100 万人投放自己的广告,但是根据经验或者画像只有 10 万的人群包,那么如何选取这 100 万,同时满足人群量级和转化(盲目选择可能存在无效用户)两个因素,就需要用到广告圈人算法模型来进行相似人群拓展了。
下图是广告推荐系统架构图:
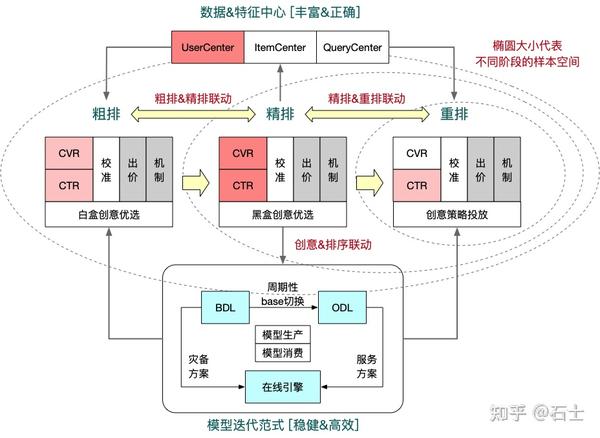
调研模型汇总
Lookalike 算法
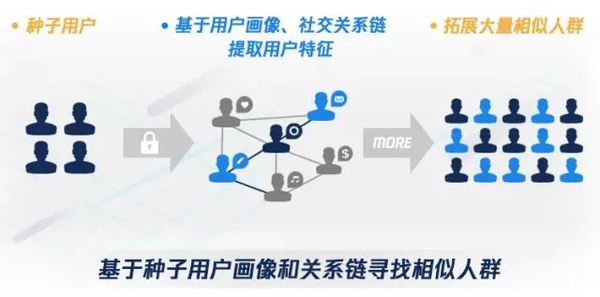
Lookalike 的目的是基于目标人群,从海量的人群中找出和目标人群相似的其他人群。
1、Lookalike 分类
Lookalike 相似人群拓展方法可以分为显示定位和隐式定位:
- 利用用户画像进行显式人群拓展:根据种子用户的标签(地理、兴趣、行为、品牌偏好等),利用相同标签找到目标人群;
- 利用机器学习 / 深度学习模型进行隐式人群拓展:广告主的种子用户做为正样本,广告平台中有海量的非种子用户,也有大量的广告投放历史数据可以做为负样本,训练机器学习模型,然后用模型对所有候选对象进行筛选。
1.1 显示定位
就是根据规则或标签进行人群选择。
基于标签选择(Rule-based)
标签本质是利用用户画像 / 标签体系(地理、兴趣、行为、品牌偏好等),基于种子用户的标签,利用相同标签的方式找目标人群。
优缺点:
- 这是最简单、高效、粗暴的一种方式。这种适合收集有大量用户数据能构建完整用户画像的公司做。
- 但这种方式试错成本高,手动调优难,投放效率低,所以往智能定向的方向发展,如协同过滤,序列推荐,图神经网络等,但很多平台仍然会提供这种传统的显示定向方式的。
应用:
腾讯 DMP 在用这种,官方介绍的原理:首先是种子用户的获取,不再局限于需要自己去收集号码包自己上传,我们还可以按照你近期账户中的系统自动记录的种子用户的数据,系统会根据种子用户的标签与腾讯用户标签做匹配,会从上百万个维度对种子人群进行分析,从中筛选出最具代表性的共有特征。根据这些特征再从全量活跃用户中筛选出另一批与种子人群最相似的用户。
1.2 隐式定位
根据具体实现的算法,可大致分为:
基于相似度 (Similarity-based),基于标签 / 用户协同过滤,基于分类模型,基于聚类,基于社交关系,基于回归模型 (Regression-based), 基于 Attention 深度模型 (Attention-based)。
1.2.1 基于相似度 (Similarity-based)
Similarity-based 是最直接的一种实现 Look-alike 的方法,其中主要是基于 user-2-user 之间的某种距离大小来衡量用户之间的相似度。主流的相似度计算方法包括:针对连续值的余弦相似度 (Cosine similarity) 以及针对离散值的(Jaccard similarity)。
计算完个体之间的距离后,如何计算个体和样本整体之间的距离有三种方法:
- 最大值 Max:利用 u1 与 seeds 中相似度最大值作为 u1 与 seeds 的相似度 sim(u1,seeds)=Max(sim(uj,seeds))
- 平均值 Mean:利用 u1 与 seeds 中每个用户的相似度去均值作为整体相似度 sim(u1,seeds)=Mean(sim(uj,seeds))
- 基于概率:该方法要求用户之间的相似度在 [0,1] 之间。通过不相似度反向得到相似度。
优缺点:
这方法计算简单,适用于小范围的计算,因为每个用户都去计算和种子用户的距离,数据量大的时候,计算量呈现指数级上升,通常会采用 LSH(Locality Sensitive Hashing ,局部敏喊哈希)的方式去加速计算,
除此之外还有皮尔森相关系数(Pearson Correlation Coefficient)、Jaccard 相似系数(Jaccard Coefficient)、Tanimoto 系数(广义 Jaccard 相似系数)。
应用:领英的《Audience Expansion for Online Social Network Advertising》。
总结: Similarity-based 非常简单,但是复杂度过高,很难在大规模数据集上进行。如果候选集的用户量是 N,种子用户量是 M,计算相似度用到的特征维度是 k 的话,那么这种算法的时间复杂度就是 O(kMN)。
1.2.2 基于标签 / 用户协同过滤
协同过滤推荐算法分为两类:基于用户的协同过滤推荐算法和基于项目的协同过滤推荐算法。
- 基于用户的协同过滤推荐算法根据用户对项目的评分矩阵,计算用户之间的相似度,找出目标用户的最邻近邻居集合,最后,对最近邻居集合进行加权,从而产生目标用户的推荐集。
- 基于项目的协同过滤推荐算法根据对用户已评分项目相似项目的评分进行预测,从某种程度上减少了评分矩阵稀疏性和冷启动问题对推荐质量的影响。
假设采用的第一种算法,基于用户的协同过滤推荐算法的核心想法是通过寻找相似的用户,然后根据相似用户的关系进行推荐。例如,用户 A 喜欢电影 a 和 c,用户 B 喜欢电影 b,用户 C 喜欢电影 a、c 和 d,通过数据可以发现用户 A 和用户 C 是是比较接近的人群,就是喜欢相同的,同时 c 还喜欢 d,那么我们可以 A 也喜欢 d 电影,向 A 推荐 d 电影。如果将用户和电影(这里指特征)看做一个点建立起了联系,关系网就形成一张图。
- 第一阶段是从种子用户找到与用户相似的用户集,基于相似度去计算(有些会从种子用户计算推荐集)
- 第二阶段根据候选集产生推荐集,先得到最后推荐集,再通过 Top-N 排序算法得到用户
1.2.3 基于分类模型
将 look-alike 看成是分类问题,很多的分类算法都可以适用。
对于特征和模型算法,不同的公司各有差异:特征取决于公司有哪些数据;在模型算法上,Facebook 和 Google 对外公布的说法就是一个预测模型,Yahoo 发表过几篇论文,详细介绍过它的算法,比如 LR,Linear SVM,GBDT 都有尝试,论文里面提到的是 GBDT 的效果比较好。下图列出了不同公司的做法,供大家参考。

(1) LR 算法
将种子用户作为正例,将随机用户进行降采样后作为负例,为每个种子训练一个 LR 模型。用这个模型在全部用户上预测,后去判断其他的用户是否为目标人群。
优缺点:
在于种子用户的所有特征都使用到,易于解释。缺点是是它是线性的,相对还是简答;随着广告的增加,索引存储、离线训练和预测的机器会难以支撑。
应用:
- 腾讯的广点通在 2015 年到 2017 年就是用这种.
- 爱奇艺广告投放 - 基于标签和基于机器学习算法(LR/GBDT/FM):https://mp.weixin.qq.com/s/ephC522bMNfo3vWDpi8j3w
- 360DMP 在 2016 年左右也是用这种。
- TalkingData 在 2015 年左右也使用这种
(2) RF 模型
根据阿里巴巴的文章,对随机森林模型的实验效果并不理想,在相同的样本和特征上 Precision 和 AUC 指标均比 LR 低,且特征重要性结果只能到特征粒度不能到特征值粒度,因此不再使用。
(3) PS-SMART 算法
根据阿里巴巴的文章,PS 架构的 GBDT 算法模型,决策树弱分类器加上 GBM 算法,具有较强的非线性拟合能力,在应用中相比其它两种算法模型效果更好。因此选择 PS-SMART 作为最终的算法模型,并对损失函数、树的个数深度、正则系数进行调优。
应用:
- 阿里巴巴的品牌目标人群优选使用 PS-SMART 算法
- 阿里策略中心年货节投放海豹项目:https://zhuanlan.zhihu.com/p/46485323
总结:
分类算法是最简单的方法,但并不是最好的方法。因为潜在兴趣用户可能存在其中 - 非种子用户 + 限制:比如非种子用户中存在曝光、点击、浏览等行为但是没有转化的用户。但是对于新广告主或者新产品,存在冷启动 (cold-start) 问题。
Regression-based 的思路根据用户特征极大化 seeds 用户的概率,对应模型很多如 LR、MF、GBDT 等。但是该方法依旧存在不足,每次营销活动都需要定制化训练模型,每次增加 item 都要重新训练模型,严重影响实时性。
1.2.4 基于聚类
根据用户标签,采用层次聚类算法(如 BIRCH 或 CURE 算法)对人群进行聚类,再从中找出与种子人群相似的机会人群,再通过 Top-N 排序算法得到用户。
1.2.5 基于社交关系
以具有相似社交关系的人也有相似的兴趣爱好 / 价值观为前提假设,利用社交网络关系进行人群扩散。
1.2.6 基于回归模型(图模型)
图模型可以分为两个阶段:
- 粗排序(Global Graph Construction):通过构造全局图找相似的用户,而构造全局图使用的是 Jaccard similarity,会带来计算量的问题,所以利用 LSH(Locality Sensitive Hashing ,局部敏喊哈希)来加速相似度的计算并构造全局图,有两种计算方法方法 MiniHash+LSH。
- 精排序(Campaign Specific Modeling):根据广告特征权重对粗排序做排序,而对特征的选择可以选择 IV(information value)或 LR(logistic regression)方法。
注:因为选择特征的时候可以用 LR,所以将这种方法放到了基于回归类型。
应用:
基于图模型的代表 Yahoo:A Sub-linear, Massive-scale Look-alike Audience Extension System
1.2.7 基于 Attention 深度模型
RALM 算法:全名 Real-time Attention based Look-alike Model,这是腾讯提出的一个基于深度学习的 Look-alike 系统,能够满足 Real-time 的要求,已经微信上的看一看应用。
它通过 user representation learning 表达用户的兴趣状态,通过 Look-alike learning 学习种子用户群体信息以及目标用户与种子用户群的相似性,从而实现实时且高效的受众用户扩展和内容触达。
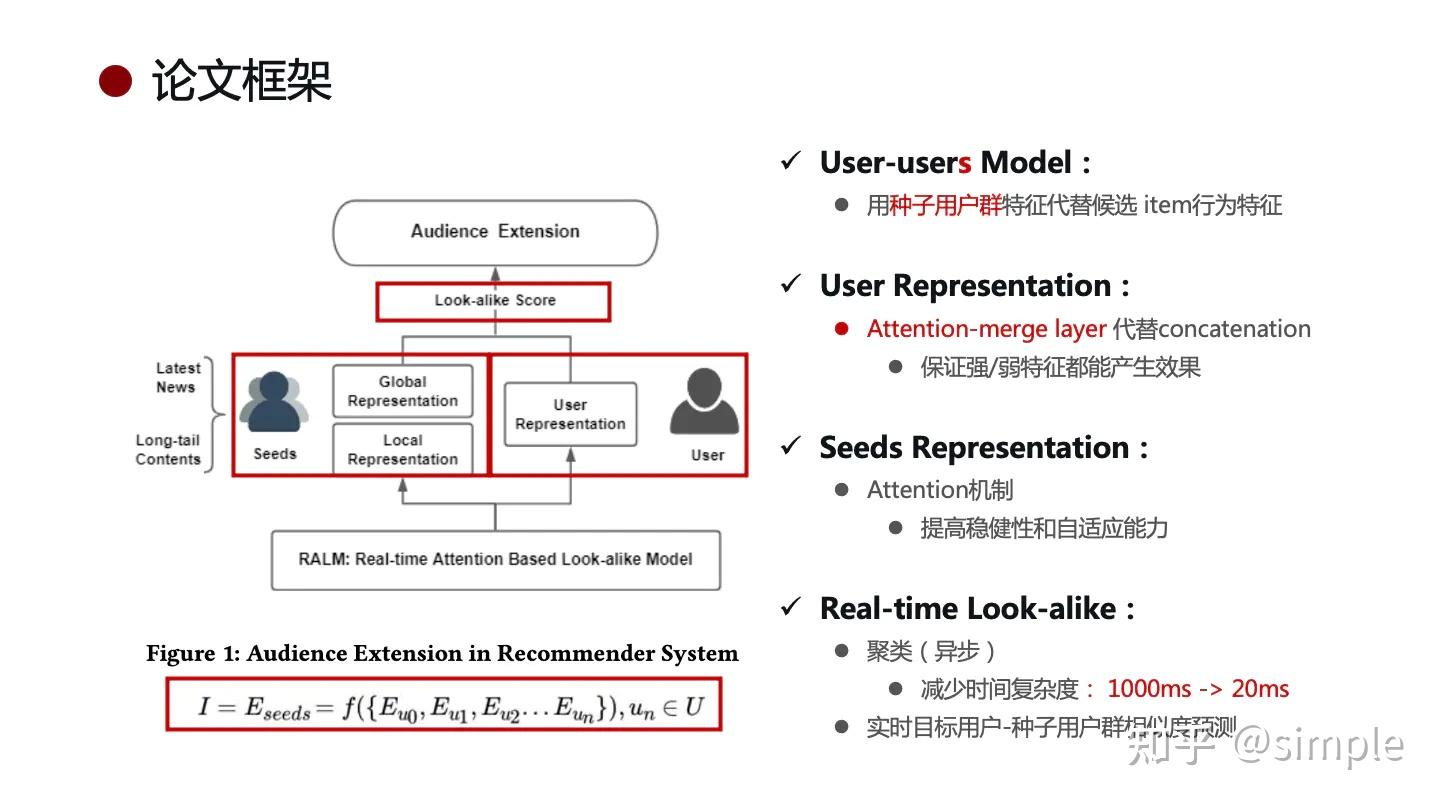
User Embedding 作为 User Representation,在 look-alike 模型中作为输入。
首先看一下整体模型结构,存在两个输入:
左侧:该 item 的 Seeds 用户,其实是 Seeds 用户的 clusters,不需要实时更新只要定时异步更新即可,
右侧:候选集的某个用户,因此模型会遍历候选集,为每个候选集用户进行计算。
之后根据模型参数和模型结构计算两种 Attention,进而计算 look-alike 得分,最后根据得分排序,输出扩展人群。
基于用户扩展的 RALM 算法框架,整个系统架构如图所示:

模型整体大致可以分为三个主要部分:离线训练、在线数据处理、在线实时预测
- 最下面离线训练:主要包括两个模型的训练:User Representation Learning(user-item 模型) 和 Look-alike Learning(user-user 模型)
- 最上面在线处理:代表 Seeds 的 clusters 结果的异步更新,这是线上定时完成的。
- 中间在线预测:遍历候选集,根据模型逐层计算的过程。因在这之前,模型输入和参数等都已准备就绪(Offline 训练搞定了 User embedding 和模型参数,而定时更新 clusters 搞定了 Seeds 端的输入),因此可以实时进行预测。
优势:
- 实时:如果出现了新的 item,它不需要重新训练模型,能够直接实时完成种子用户扩展
- 高效:在保持 CTR 前提下加强对于长尾内容的挖掘和推荐,获得更准确和更具多样性的用户表达
- 快速:降低了计算复杂度,精简预测计算,满足线上的耗时性能要求
应用:
- 微信看一看使用 RALM 算法
- Adobe 的用的是 TraitWeight algorithm
- 百度用深度神经网络相似排序模型
注:由于性能的因素,部分厂家会使用两级模型,就是第一级别是基于标签的,因为基于标签的方式简单,能够做初步筛选,其实就是做粗排,第二级别的是基于算法的,做精选。
参考:
五个工业风的 Look-alike 系统介绍:https://zhuanlan.zhihu.com/p/386684545
https://www.jianshu.com/p/cb326468ff7e
https://zhuanlan.zhihu.com/p/370467639